


TIL
Today I Learned!
ansible, aws, bash, docker, elastic search, frontend, homebrew, intellij, java, jenkins, linux, macos, mongodb, network, ngrok, nodejs, openssl, postfix, python, resilience, security, ssh, strace, subversion, tailwindcss, terraform, yum
Services I have helped run in the past
- Sending email
- Email is delightful :)
Ansible
ansible-playbook -i "localhost" playbook-nagios.yml --list-tasks: Lists plays that will be run by ansibleansible hostgroup -i inv -m shell -a "command": Execute taskacross all hosts in group hostgroup in inventory inv
# Don't make any changes but print a diff of what would have changed
# Note: It's not always possible to do a check run
ansible-playbook -i inv pb.yml --check --diff
AWS
aws sts get-caller-identity: Gets the apiuser for my current apikey
Bash
Beautiful bash
- gradlew
- locust run-redistributed-headless.sh This one has a nice capture of process ids in an array with looping
- Github checks ssh key encryption algorithm in use
- Zed script directory
- Pleroma web site build script
More links
- Documented bash ‘set’ shell modifiers (eg What does set -e mean?)
- Best practices for writing bash
- Anybody can write good bash
- Google’s style guide: Lots of great tips / things to think about here
- Difference between [ and [[: Always have to look this up
- Shell check for static analysis of scripts looking for common mistakes
#!/usr/bin/env bash
# Default values for env variables
VERBOSE=${VERBOSE:-0}
# Prefer env vars to args
VERBOSE=0 deploy.sh
# Parse args
while getopts "hp:i:" opt ; do
case ${opt} in
h)
kube::test::usage
exit 0
;;
p)
PARALLEL="${OPTARG}"
if ! isnum "${PARALLEL}" || [[ "${PARALLEL}" -le 0 ]]; then
kube::log::usage "'$0': argument to -p must be numeric and greater than 0"
kube::test::usage
exit 1
fi
;;
i)
kube::log::usage "'$0': use GOFLAGS='-count <num-iterations>'"
kube::test::usage
exit 1
;;
:)
kube::log::usage "Option -${OPTARG} <value>"
kube::test::usage
exit 1
;;
*)
# default case if nothing above matches
kube::test::usage
exit 1
;;
esac
done
# Check that a file exists
if [[ -f /path/to/file ]]; then
echo "file exists"
elif [[ -f /path/to/file1 ]]; then
echo "file1 exists"
else
echo "file does not exist"
fi
# Declare a function, call a function
greet () {
local name=$1
echo "hello, world $name"
}
greet 'Christian'
# Here's an example of a script that wraps a command
# to access a remote k8s environment
#!/usr/bin/env bash
if [[ $# < 1 ]]; then
echo "Usage: $0 [production|staging|...]"
exit 1
fi
export ZED_KUBE_NAMESPACE=$1
pod=$(kubectl --namespace=${ZED_KUBE_NAMESPACE} get pods --selector=app=zed --output=jsonpath='{.items[*].metadata.name}')
exec kubectl --namespace $ZED_KUBE_NAMESPACE exec --tty --stdin $pod -- /bin/bash
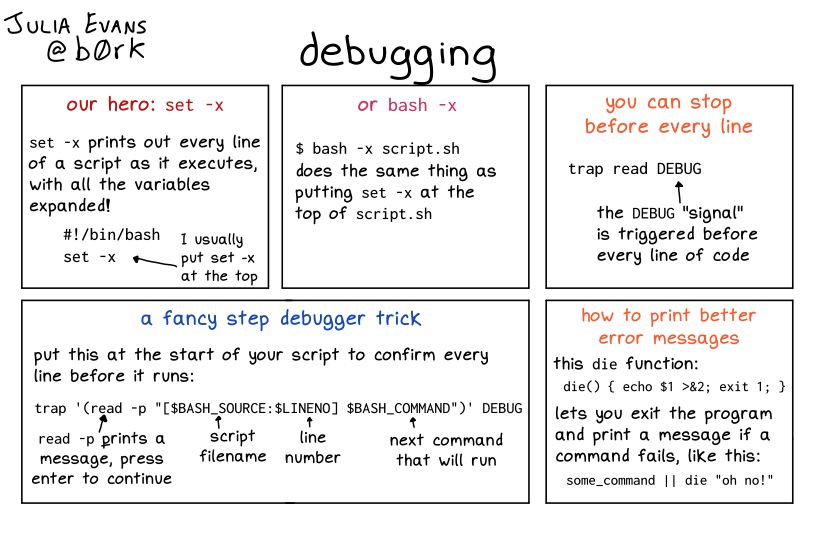
# Debugging
In the bash man page there is a section for 'set' type options ...
The following set of defaults can be revealing. It will probably reveal passwords though in any output collected from a command. Be careful!
set -euxo pipefail
* e exit immediately if a command exits with non-zero status
* u treat unset variables as an error during parameter expansion and exit
* x display all simple commands after parameter expansion
* o pipefail return value of a pipeline is the last command to exit with non-zero status
# Fail when:
# Attempting to use a var that hasn't been set
# A command fails
# A command in a pipeline fails
set -o nounset
set -o errexit (same as set -e)
set -o pipefail
# Looping
DIRECTORIES="vim bash zsh various"
for dir in $DIRECTORIES; do
echo "Setting up symlinks for all items in $dir"
# ...
done
Docker
The difference between entrypoint and cmd
The ENTRYPOINT specifies a command that will always be executed when the container starts.
The CMD specifies arguments that will be fed to the ENTRYPOINT.
If you want to make an image dedicated to a specific command you will use ENTRYPOINT [“/path/dedicated_command”]
Otherwise, if you want to make an image for general purpose, you can leave ENTRYPOINT unspecified and use CMD [“/path/dedicated_command”] as you will be able to override the setting by supplying arguments to docker run.
Elastic
CAT api
Management urls in elastic that give cluster status, and index info
- _cat/nodes return info about cluster nodes (jvm use, cpu, leader / follower + several other things) elastic docs
- _cat/master return info about this cluster’s leader node
- _cat/indices return info about an index (number of primary+replica shards, disk use, health)
- _cat/shards return shard stats (primary or replica, disk use, node)
- _cat/allocation?v return shards to data nodes (disk use)
?v prints columns with output and tries to line up data
Notes
- Can add replicas easily but merging shards is hard
- Dedicated leader nodes means less data copying during failover in aws
- Production clusters should have an odd number of nodes (3 or 5 are common for small clusters. the latter tolerates 2 node failures while continuing to be operable)
- Without dedicated leader nodes, a cluster can become very busy after a failure copying data (high network, cpu are observed)
- Cluster nodes should be “big enough” to handle this extra load
- Running elastic with a high availability requirement in production is expensive $$$
- 20% storage is reserved for elastic overhead by aws opensearch
- Aws opensearch says cluster with standby has 99.99% avail and doesn’t copy shards as aggressively (or at all?) during a failure
- This config automatically added dedicated leader nodes x3
- A cluster without standby has 99.9% avail
Frontend
- html5boilerplate a reasonable starting point for frontend projects. Pretty much everything you could ever be worried about is here 🙂 This is similar but much simpler
- Vue instance lifecycle events
- Setting up Vue computed properties for unit tests with vue-test-utils In the past, I have had to override a computed value to create specific test context
Homebrew
# Status of all services
brew services
# Start a service
brew services start [service]
# Stop a service
brew services stop [service]
Intellij
Shortcuts
- Cmd+Shift+V Choose from previous n clipboards values and paste
- Ctrl+g Multi select the word under the cursor (need to press multiple times)
- Alt+Cmd+[ jumps to matching opening brace
- Alt+Cmd+] jumps to matching closing brace
Java
- Java links that are my favourites
- Db migrations in java: Incredibly Spring data doesn’t have a story for db migrations out of the box (It seems to have everything else!)
- Elasticsearch’s guidance for setting java’s heap size: 50% of main memory available in a system is a recommendation I’ve read in a couple of places now
- Get version of the jvm that ran tomcat by looking at catalina.out for log lines: [‘JVM Version’, ‘JVM Vendor’]
# Show information about jvm vendor
java -XshowSettings:properties -version
# Interpreting a garbage collection line
2023-02-12T16:58:32.425-0500: 154220.773: [GC (Allocation Failure) [PSYoungGen: 5152746K->150498K(5278720K)] 8630240K->3628228K(9599488K), 0.1430319 secs] [Times: user=0.21 sys=0.01, real=0.14 secs]
* This is a detailed gc event log that includes info about Eden (YoungGen) and Tenured (OldGen). Start the jvm with '-verbose:gc -XX:+PrintGCDetails'. There are other settings that specify where to write log events.
* Allocation failure means no space is left in Eden
* [PSYoungGen: n -> m(x)]: Size of eden before collection -> Size of eden after collection(Total eden size)
* [] n -> m(x): Size of tenured before collection -> Size of tenured after collection(Total tenured size)
* Followed by gc event time in seconds
* Is this considered a minor collection or full? I think minor because the event starts with GC (...). Full collection starts with FULL GC (...).
* [Source](https://www.baeldung.com/java-verbose-gc)
* Get installed tomcat version
java -cp /path/to/tomcat/lib/catalina.jar org.apache.catalina.util.ServerInfo
A full garbage collection is triggered when a copy from newgen to oldgen fails because there isn’t enough available memory.
Set default java on macos
# Get a list of installed java versions
/usr/libexec/java_home -V
christian@Christians-Mac-mini cleskowsky.github.io % /usr/libexec/java_home -V
Matching Java Virtual Machines (15):
19.0.2 (arm64) "Amazon.com Inc." - "Amazon Corretto 19" /Users/christian/Library/Java/JavaVirtualMachines/corretto-19.0.2/Contents/Home
17.0.7 (arm64) "Amazon.com Inc." - "Amazon Corretto 17" /Users/christian/Library/Java/JavaVirtualMachines/corretto-17.0.7/Contents/Home
17.0.6 (arm64) "Amazon.com Inc." - "Amazon Corretto 17" /Users/christian/Library/Java/JavaVirtualMachines/corretto-17.0.6/Contents/Home
17.0.1 (arm64) "Azul Systems, Inc." - "Zulu 17.30.15" /Users/christian/Library/Java/JavaVirtualMachines/azul-17.0.1/Contents/Home
17.0.1 (x86_64) "Amazon.com Inc." - "Amazon Corretto 17" /Users/christian/Library/Java/JavaVirtualMachines/corretto-17.0.1/Contents/Home
11.0.11 (arm64) "Azul Systems, Inc." - "Zulu 11.48.21" /Users/christian/Library/Java/JavaVirtualMachines/azul-11.0.11/Contents/Home
...
# Then pick the version this way
export JAVA_HOME=`/usr/libexec/java_home -v 17.0.7`
# Maven skip tests
mvn package -DskipTests
Performance analysis
CPU
# If cpu usage is high, dumping threads in the jvm may help
# identify what work is being done. Taking multiple dumps
# at 10s intervals will help spot threads that have been running,
# or been blocked for a long time.
#
# If a problem is lots of threads running for a short amount
# of time, a 10s interval may not show that readily. (I should
# look into java flame graphs for java!)
#
# Intellij can help analyze thread dumps. Look for the analyze
# thread dump action.
jstack <pid>
# A stronger version
sudo jstack -F <pid>
Links
Memory
# Look at garbage collection stats in the jvm
sudo jstat -gcutil -h10 1002 250 20
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 100.00 100.00 93.19 90.39 276 36.911 10510 53321.125 53358.036
0.00 0.00 100.00 100.00 93.19 90.39 276 36.911 10510 53321.125 53358.036
0.00 0.00 100.00 100.00 93.19 90.39 276 36.911 10510 53321.125 53358.036
...
S0 - surviver space 1 utilization
S1 - surviver space 1 utilization
E - Eden space utilization
O - Old gen space utilization
M - ?
CCS - ?
YGC - # of young garbage collections
YGCT - young gc time (units?)
FGC - full garbage collections
FGCT - full garbage collection time
GCT - garbage collection time
Collect 20 samples, from java process with pid 1002, at 250ms intervals,
and reprint the header every 10 lines of output
No header line
sudo jstat -gcutil <pid> 250 7
JConsole
A program that ships with the jdk that lets you introspect a running java process. (You can see exposed jmx beans, heap memory, threads, and a few other things) I usually use it to look at jmx beans
# Figure out the pid of your java process doing something like this or pidof ...
ps aux | grep java
# The run
jconsole
# JConsole will display a list of java processes it finds on your system. Pick the one you want!
Note: I have only ever done this in dev
Maven
# Compute dependency tree for a package in a java program that was brought in by a maven dependency either directly or indirectly
# All dependencies
mvn dependency:tree
# Filter output from above
mvn dependency:tree -Dincludes=org.yaml
Links
- How root / intermediate certs work, and how they’re protected
- A list of tutorials from Baeldung.com. This is a really good resource!
- Testing in Java
- Java logging: sl4j, apache commons logging, log4j, java.util.logging … All the logs! Nice overview of logging in java with increasing degrees of complexity depending on need
- Analyzing maven dependency tree
Openssl
Cacerts, keystores, trust, pkcs12, trust anchors, WebPKI
# View trusted root certs in centos
keytool -list -keystore /etc/pki/ca-trust/extracted/java/cacerts -storepass changeit
# View an ssl cert from a remote host
openssl s_client -showcerts -connect telusemrapi.telushealth.com:443
# View a particular cert in my trust store
# Get alias from the cert list command above
keytool -list -v -keystore /etc/pki/ca-trust/extracted/java/cacerts -alias digicertassuredidrootca -storepass changeit
View keys in a key store
keytool -list -v -keystore a.p12 \
-storepass changeme \
-storetype PKCS12
Extract key
openssl pkcs12 -info -in a.p12 -nodes -nocerts
Extract cert
openssl pkcs12 -info -in a.p12 -nokeys
Make a keystore
openssl pkcs12 -export -in cert.pem -inkey key.pem -out a.p12
# Generate a private key in pem format
openssl genrsa -out key.pem 2048
# Then do this if I need a public key too
openssl rsa -in key.pem -outform PEM -pubout -out public.pem
# Generate a public/private key in rsa format (Can be used with github + SSH)
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
# Github recommends creating a key with the ed25519 algorithm
ssh-keygen -t ed25519 -C "your_email@example.com"
# Check a certificate
openssl x509 -in server.crt -text -noout
# Check a key
openssl rsa -in server.key -check # for rsa keys
ssh-keygen -l -f my_ed25519_key # for ed25519 keys
# Check a csr
openssl req -text -noout -verify -in server.csr
# Verify a certificate against a private key
# Extract public key from cert
> openssl x509 -in server.crt -noout -pubkey > public_key_from_cert.pem
# Derive the public key from private key
> openssl pkey -in server.key -pubout -out public_key_from_private_key_derived.pem
> diff public_key_from_cert.pem public_key_from_private_key_derived.pem
Linux
zip -er a.zip a/: Creates an encrypted zipfile of contents with folders from a/dd if=/dev/zero of=a.txt bs=1024 count=10240: Create a 10m “empty” file for testing (10k chunks, at 1024 bytes per chunk)pstree -s tomcat: Show processes containing tomcat in their commandline (brew install pstree)split -l 50 filename: Splits file into 50 line chunks names xaa, xab, xac, …mkfs.xfs /dev/sdc: Make an xfs filesystem- After initializing a volume with a filesystem, get its UUID by running
sudo blkidand update /etc/fstab. Don’t use the device file in fstab. (eg /dev/nvme1n1) Device name to volume mapping can change between restarts depending on which volume comes up first when multiple volumes are attached to a server. - Background long running tasks started in a login shell
- Run
bgthendisown -hto tell your shell not to send the terminate signal to processes started under it. (Ignore SIGHUP?) Suspend the program first with ctrl-z. - Run
nohup <cmd>to launch a command not bound to the lifetime of the current shell.
- Run
- Disk utilization per process with pidstat
pidstat -dl 20batches and reports disk use (r/w) every 20s source - Filesystem Hierarchy Standard: Where to put things in the linux file system
nc -l 8080 -kstarts a tiny echo server that prints incoming client messages
Systemd
Systemd stops mongodb by sending a sigterm signal. Sigterm is like asking a process to terminate itself gracefully. It’s the default when you do a kill
SIGTERM is the “normal” kill signal. The application will be given time to shut down cleanly (save its state, free resources such as temporary files, etc.), and an application that is programmed to not immediately terminate upon a SIGTERM signal may take a moment to be terminated.
SIGKILL (also known as Unix signal 9)—kills the process abruptly, producing a fatal error. It is always effective at terminating the process, but can have unintended consequences. SIGTERM (also known as Unix signal 15)—tries to kill the process, but can be blocked or handled in various ways.
https://stackoverflow.com/questions/42978358/how-does-the-systemd-stop-command-actually-work
Always want to be doing sigterm.
Links
- Tcpdump: A great guide to using tcpdump to investigate network traffic in a vm running a relatively modern version of linux.
MacOS
cmd + shift + .Reveals hidden files in a finder window. eg ~/.sdkman/cmd + .Is a special key combo for the physical escape key on the iPad magic keyboardcmd + ctrl + spacePops up the emoji keyboard on a macdefaults write -g ApplePressAndHoldEnabled -bool falseDisables key hold for accented characters (I hold a key to move a cursor in vim)
MongoDB
# Takes a logical backup
mongodump --archive=a.gz --gzip --db a
mongodump --uri "$(get_db_uri a)" --archive=a.gz --gzip --db a
# Restores a logical db backup
mongorestore --archive=a.gz --gzip
mongorestore --archive=<db dump>.gz --gzip --nsFrom='<source_db>.*' --nsTo='<target_db>.*'
# List engine type (default should be WiredTiger since 3.2+)
db.serverStatus().storageEngine
db.serverStatus() # is kinda interesting in general
# a few basic commands that give me a sense of a mongod server
show dbs
use <db>
show collections
db.collection.find({})
db.collection.insertOne({
"a": 1
})
# Export all or part of a collection as CSV
mongoexport --db <db> --collection <coll> --type=csv --query "{ x: value, y: value }" --fields "<field1>,<field2>,..." -u<user>
# Exports using a uri connection string
mongoexport --uri="mongodb+srv://user:password@host/db?replicaSet=rs0&ssl=false" --collection col --type=csv --fields "field1,field2"
# An export example with a date because I always have to look this up :'(
mongoexport --db <db> --collection <coll> --type=csv --query '{ "creationDate": { "$gte": { "$date": "2023-11-01T00:00:00.000Z"} } }' --fields 'field1,field2,...' -usupport
# Get status of replicaset member in startup2 state (Newly added to a replicaset and not fully synced)
# Version dependent
# [Source](https://docs.mongodb.com/manual/reference/command/replSetGetStatus/)
# Mongodb for v3.4 -> v4.2
db.adminCommand( { replSetGetStatus: 1, initialSync: 1 } )
# Add an element to an array on an existing doc
# Use the $push operator :)
db.collection.update({ filter criteria }, { $push: arrayName: 'new item' } })
# Eval a command from the command line
# Stuff like 'show dbs' doesn't work but js commands do. Sometimes this is helpful in script work
mongo ocean --eval 'db.audit.count()'
# Get top 5 sizes of docs in collection coll
# For some reason I can't find official documentation for bsonsize(...) !!
var x = [];
db.coll.find().forEach(function (p) {
x.push(bsonsize(p));
});
print(x.sort().reverse().slice(0, 5));
# Stats like storageSize, number of collections + indexes, avgObjSize, and a few other things
use db
db.stats()
# Get slowms option that logs queries slower than x milliseconds
db.getProfilingStatus()
# To change slowms
db.setProfilingLevel(0, { slowms: x })
Connection Strings
# DNS seed list (Mongodb > 3.6)
# We can setup a srv record that contains many or all hosts in a mongodb
# replica set
mongodb+srv://db.cluster.env/dbname
# This will pull a list of ips,ports from that srv record and connect to
# one host. After successfully connecting to the replicaset it will ask the
# rs for further hosts
#
# There are options that can be passed along with this (standard ones) and
# this mode can also lookup a corresponding TXT record to get the replicaset
# name + authdb
# Standard connection string
mongodb://[username:password@]host1[:port1][,...hostN[:portN]][/[database][?options]]
# You can explicitly list all members of a replica set using this method
# I believe the driver only needs to find one replica set member and then
# can discover others and even follow mongo elections
Links
- Connection strings
- Blog post about Mongo 3.6 and dns seeding
- Another blog post about service discovery: This one is particularly good. Walks you through a connection lifecycle in pyMongo. (I’m assuming a recent java driver is similar) There’s a formal service discovery protocol it sounds like
- db.isMaster(): The query drivers send to the mongo host they’re configured with to learn about the topology of a mongo cluster
- Update arrays in a document: Modify an array in a document using $ and $[] notation
- Design Patterns for MongoDB
- Compact command concerns
- Mongodb manual - compact
# Find all users in a db cluster regardless of db they're created under
PRIMARY> use admin
PRIMARY> db.system.users.find()
Network
# Visualize cidr blocks with ipcalc
christian@Christians-Mac-mini cleskowsky.github.io % ipcalc 10.1.2.0/16
Address: 10.1.2.0 00001010.00000001. 00000010.00000000
Netmask: 255.255.0.0 = 16 11111111.11111111. 00000000.00000000
Wildcard: 0.0.255.255 00000000.00000000. 11111111.11111111
=>
Network: 10.1.0.0/16 00001010.00000001. 00000000.00000000
HostMin: 10.1.0.1 00001010.00000001. 00000000.00000001
HostMax: 10.1.255.254 00001010.00000001. 11111111.11111110
Broadcast: 10.1.255.255 00001010.00000001. 11111111.11111111
Hosts/Net: 65534 Class A, Private Internet
Tools
- NetSpot: Map out areas of strong vs weak wifi signal strength to help you decide where to put wireless access points. There’s a free version!
Ngrok
- ngrok: A tool to create a public tunnel to a tcp service running on localhost
OpenSSL
Cross posted a few ssh things here because I can never remember where in this doc I put stuff like this …
# Check a certificate
openssl x509 -in server.crt -text -noout
# Check a key
openssl rsa -in server.key -check
# Check a csr
openssl req -text -noout -verify -in server.csr
# Generate a private key in pem format
openssl genrsa -out key.pem 2048
# Then do this if I need a public key too
openssl rsa -in key.pem -outform PEM -pubout -out public.pem
# Generate a public/private key in rsa format (Can be used with github + SSH)
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
# Github recommends creating a key with the ed25519 algorithm
ssh-keygen -t ed25519 -C "your_email@example.com"
Postfix
Various helpful commands
# Re-enqueue messages held back for a few days (Resets their timestamp
# for remaining in delivery queues)
postsuper -r [<QUEUEID>|ALL]
# Generates a report about messages in postfix queues, by email domain
# and time spent in queue (works for other postfix queues too!)
qshape deferred
# Get me a list of messages currently in the active queue (and possibly
# other queues eg hold)
mailq
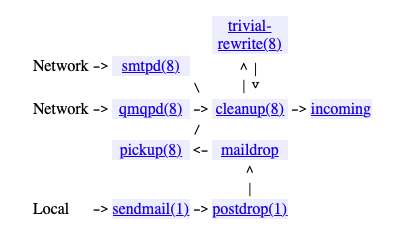
Email entering postfix queues
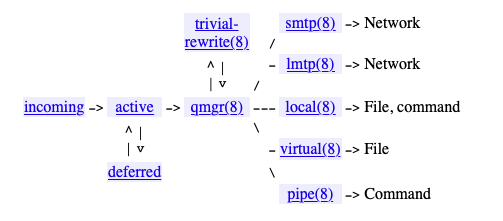
Email leaving postfix
Postfix log entry
# Message delivery time stamps
# delays=a/b/c/d, where
# a = time before queue manager, including message transmission
# b = time in queue manager
# c = connection setup including DNS, HELO and TLS;
# d = message transmission time
- The postfix logfile entry: Postfix feature # 20051103 added the following (from the 2.3.13 release notes): Better insight into the nature of performance bottle necks, with detailed logging of delays in various stages of message delivery. Postfix logs additional delay information as “delays=a/b/c/d” where a=time before queue manager, including message transmission; b=time in queue manager; c=connection setup time including DNS, HELO and TLS; d=message transmission time.
A few more links about postfix :)
- Postfix architecture (input handlers, queues, output handlers): Fairly important for understanding how postfix works
- SPF records: Qualifiers, mechanisms, oh my! This is a way to validate the FROM address of a message. That the sender (ip) is permitted to send email on behalf of the domain in from:. Works with dns
- Basic postfix config: Good high level guidance for setting up postfix for specific use cases
- Extend postfix smtpd input filtering with custom code: We were looking for a way to show backpressure to clients based on health of active and deferred queues (Don’t accept new messages addressed to email service providers we are currently having delivery trouble with. eg A large number of delayed messages). This may be a way to do that
- On destination rate delays: If you are relaying directly to email service providers, the rate means 1 per domain. If indirect on the other hand, domain == ‘smtp nexthop’. If you only have one of these – ie you’re sending messages to an internal smtp server that relays through another before external delivery – domain in this case is NOT the recipient address domain. It is the relay server. If you only have 1 of these, then email will go out 1 at a time at the defined period
Reverse DNS (ptr) records
Mail servers will cross-check your SMTP server’s advertised HELO hostname against the PTR record for the connecting IP address, and then check that the returned name has an address record matching the connecting IP address. If any of these checks fail, then your outgoing mail may be rejected or marked as spam.
So, you need to set all three consistently: The server’s hostname and the name in the PTR record must match, and that name must resolve to the same IP address.
Note that these do not have to be the same as the domain names for which you are sending mail, and it’s common that they are not.
Reverse dns records (ptr): A discussion of how they’re used. The first comment is the most helpful (Included here for posterity :))
Python
python3 -m http.server 8000: Runs an http server in the current dirpython3 -m site: Lists python’s module load path
Resilience
Security
Security, cryptography, whatever
- Choosing good cryptographic constructs for specific circustances Cryptographic Right Answers
- Generate a random secret on linux / mac:
Alpha numeric
dd if=/dev/urandom bs=16 count=1 2> /dev/null | xxd -p
Uppercase, lowercase, numbers, +, =, /
head -c 32 /dev/urandom | base64
SSH
~/.ssh/config
# Create an vm alias that's easier to remember than an ip
# Then use it thusly: ssh m
Host m
Hostname <ip address>
User <login user>
IdentityFile ~/.ssh/<key file>
# ControlMaster
#
# Reuse connections when re-connecting to a host with an already established
# one. (Note: The directory ~/.ssh/sockets must already exist.)
Host *
ControlMaster auto
ControlPath ~/.ssh/sockets/%r@%h-%p
ControlPersist 600
Create an ssh tunnel to allow access to an internal service where I do have a jump host and can connect to another machine that can see the internal service
ssh -L 10000:[vm.internal:443] [jump.host]
* 10000 Local port to bind ssh to (Point browser here)
* vm.internal:443 Internal service host:port
* jump.host A bastion vm I can ssh to
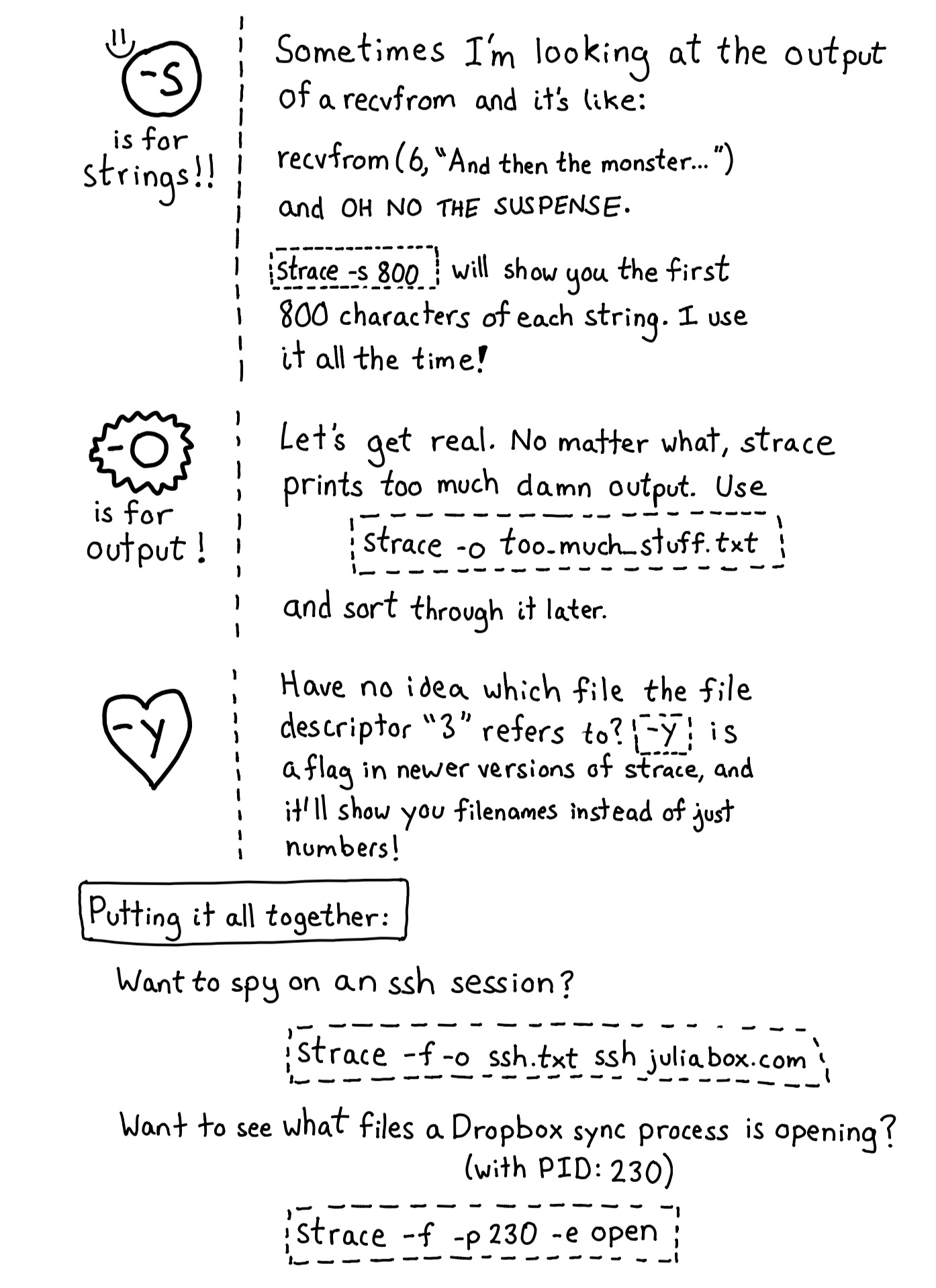
Strace
strace
-e trace=open,pread64 Trace only open and pread64
-p <pid> The process id to attach to. Optional
-s 2000 Event line length to print
-f Strace should follow subprocesses
[command] Strace will run this command and begin a trace

Subversion
# Cherry pick a changeset from the specified branch in the repo
svn merge -c x ^/operations
# Show the most recent commit
svn log -l 1
- Convention at cog
- For a merge commit message, start with “Merged from
" - Add a re #
- For a merge commit message, start with “Merged from
Tailwindcss
# Quick and dirty launch tailwind cli (using springboot here)
# Note: This is not appropriate for inclusion in a build script (Use postcss or some such for that)
npx tailwindcss -i ./src/main/resources/static/css/site.css -o ./target/classes/static/css/site.css --watch
Terraform
# Use tfenv to install multiple versions of terraform at once
# See : https://github.com/tfutils/tfenv
# Install with
brew install tfenv
# Install a version of tf
tfenv list-remote
tfenv install <v from output of list-remote>
# Make the new installed version of tf current
# Switch between versions of tf with `tfenv use`
tfenv use <v>
# Enable verbose logging
# https://www.terraform.io/internals/debugging
# TF_LOG=[TRACE, DEBUG, INFO, WARN or ERROR]
TF_LOG=DEBUG terraform plan -out a.plan
# Generating a lock file that's good for arm64, amd64
terraform init --backend=false --upgrade
terraform providers lock -platform=darwin_amd64 -platform=darwin_arm64 -platform=linux_amd64
Yum
# list installed packages
yum list installed
# list package updates
yum check-update
# list package updates (security only)
yum check-update --security
# apply updates
yum update
# apply security updates
yum update --security
# get info about a package
yum info python3
# Purge old package information. Can get chunky sometimes!
yum clean packages
yum clean headers
yum clean metadata
yum clean all # this is probably all I need :)
NodeJS
- npx serve - Runs a tiny webserver in the current directory. Very handy!
- npm install -g npx - Installs npx assuming you have npm :)