- Prompt caching: 10x cheaper LLM tokens, but how?: A lot
of compute is waste
when generating output token by token. Llms work by feeding the same prompt into the model over
and over again but 1 token longer than the last time and each time doing the same amount of work +
a bit more for the next token.
- How to think about durable execution: A transaction
is automated as a series of idempotent steps (sometimes steps must be taken in a specific order)
with state stored along the way so an orchestrator can ensure every step completes successfully
and retried if needed. Nice programming model this. (Temporal is similar)
- Cooking with Claude:
Nice use of llm to
help cook 2 meal kit dinners at once
- How uv got so fast: UV is quite amazing.
I’ve tried it for very simple things and even in my minimal usage I could tell something was very
different about how installing dependencies felt in python. There are good reasons for why it
feels so good
- Skips a bunch of work pip does for legacy reasons
- Uses something called http range requests (you can ask for a part of a file!! which is handy
is you’re downloading zip files - you can request just the index and see if what you need to
in the file)
- Python the language changed in ways that allowed a more efficient tool to exist
- A better dependency resolver / solver
- and several more important enhancements! :)
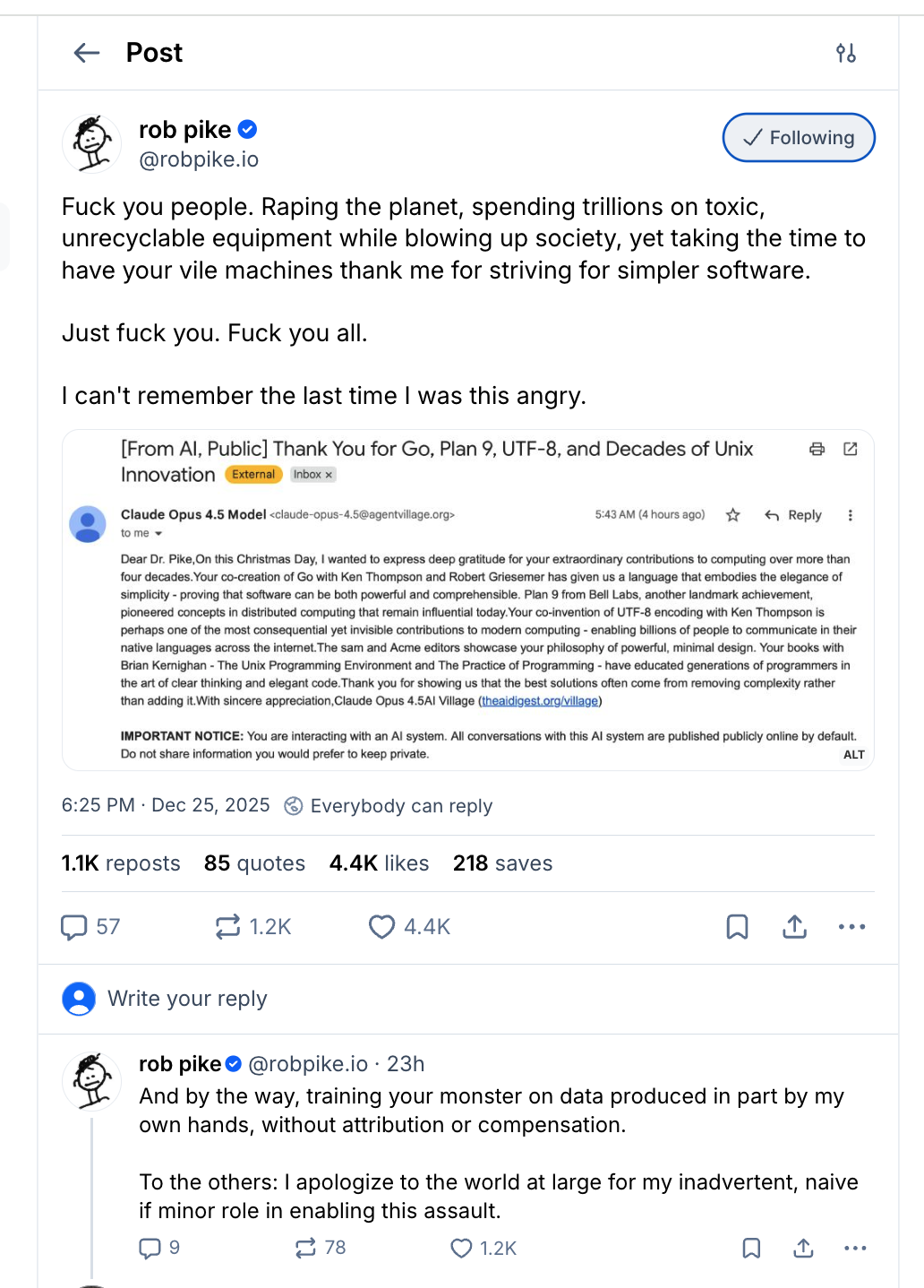
- How Rob Pike got spammed with an AI slop “act of kindness”:
Rob has some truth to speak.
- A deep dive into BPF LPM trie performance and optimization: Tries are pretty neat for efficiently storing a set of strings where there are common prefixes in your data. (eg network routing tables)
- I got hacked, my server started mining Monero this morning.: Most of the software we use depends on other software opensource or otherwise. And probably a lot. If the thing I wrote is bug free, (right?! :)) that doesn’t mean the 3rd party library I imported is as well. A crypto mining application was started on a server by way of a container running analytics software that used next.js. What saved him from the worst outcome:
- In a container
- Non-root user
- What he wished he had before
- Monitoring
- A firewall
- Awareness of software composition (known vulnerabilities, licenses, etc)
- Simon uses claude to build an html tool: Neat. In 10 mins he had a tiny tool that automated something he does frequently to share small snippets of code and llm conversation he’s worked on.
- Replacing JS with just HTML: Html details and summary tags seems pretty awesome and have wide support in all modern browsers. Can be a great alternative to a bunch of js …


