Weekly Notes
- Load balancing Amazon ECS services with a Kubernetes Ingress Controller style approach: Edge architecture that uses an nlb in front of nginx. We’re considering doing something similar with Traefik at work.
- Restructuring How We Think About Alerts: Prefer informational alerts that don’t try to tell you what the problem is. You will always have to investigate and if the guidance from an alert is wrong you’ve spent time looking into the wrong problem.
- The Most Important Developer Productivity Metric: Time to build a package a deployable unit is an important metric. The longer it takes to build the harder it is to debug a production issue sometimes. More than 10m starts to feel bad.
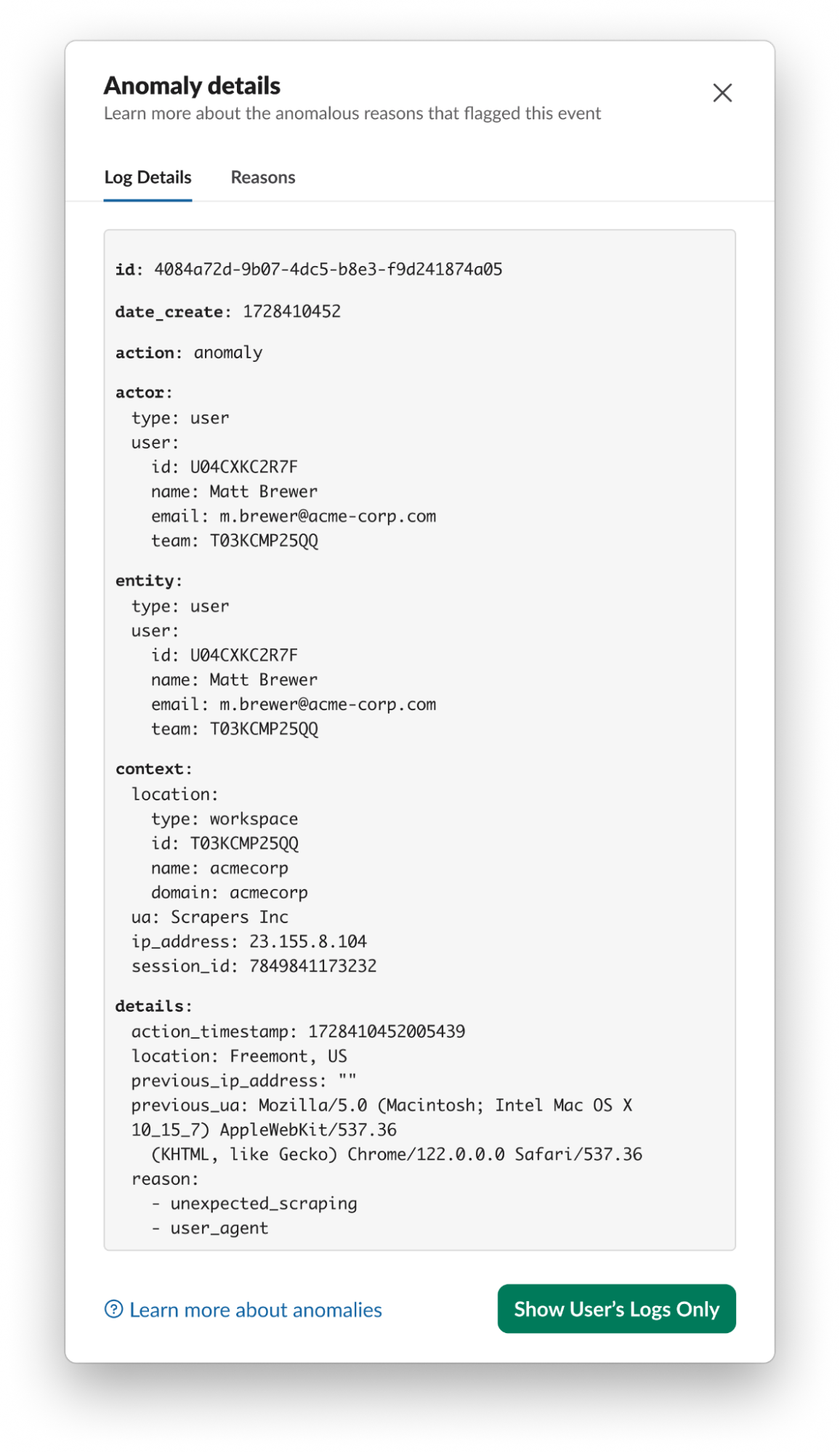
- Slack Audit Logs and Anomalies: Audit logging at slack + security event monitoring at the application level.
- AI Mistakes Are Very Different from Human Mistakes: Essay from Bruce Schneier about LLMs and how they aren’t like people when they mess up. They lie confidently and are seemingly unaware of the boundaries of their competence.
- AWS re:Invent 2024 - Try again: The tools and techniques behind resilient systems (ARC403): Lots of ideas here from Marc Brooker @ reinvent 2024:
- Retries
- Jitter is good
- Can cause a struggling system to fail harder
- Backoff doesn’t work in open systems (where clients don’t get feedback about health)
- Circuit breakers
- Can be problematic
- Trouble in one area of an integration can disable everything (partial failure becomes total)
- Flatten tail
- Try sending multiple identical requests and take the first answer that comes back
- Have to tolerate multiplying capacity needs
- Might be worthwhile in certain scenarios
- Simulations
- Can test effect of certain behaviours this way
- Example
- Retries
- Bridgy Fed technical design: Nice walkthrough of what this system looks like and some of the choices made.
- Facebook chef cookbooks: Fb has outsourced all the code used to configure servers
- Facebook chef repo guiding principles: Describes how to think about the process of converging servers towards a central source of configuration policy
- Build your own role-playing game: the business continuity plan drill: Nice overview of how to carry out a business continuity / disaster recovery drill