- MongoDB Sizing Guide: Good, empirical advice on how to come to an approximate sizing for a new cluster if you have a sense of how much data you’re going to be storing.
- Handling exceptions in spring mvc: Write an exception and tag it with an annotation include status and error message. This is pretty damn elegant. If you can figure the magic! :)
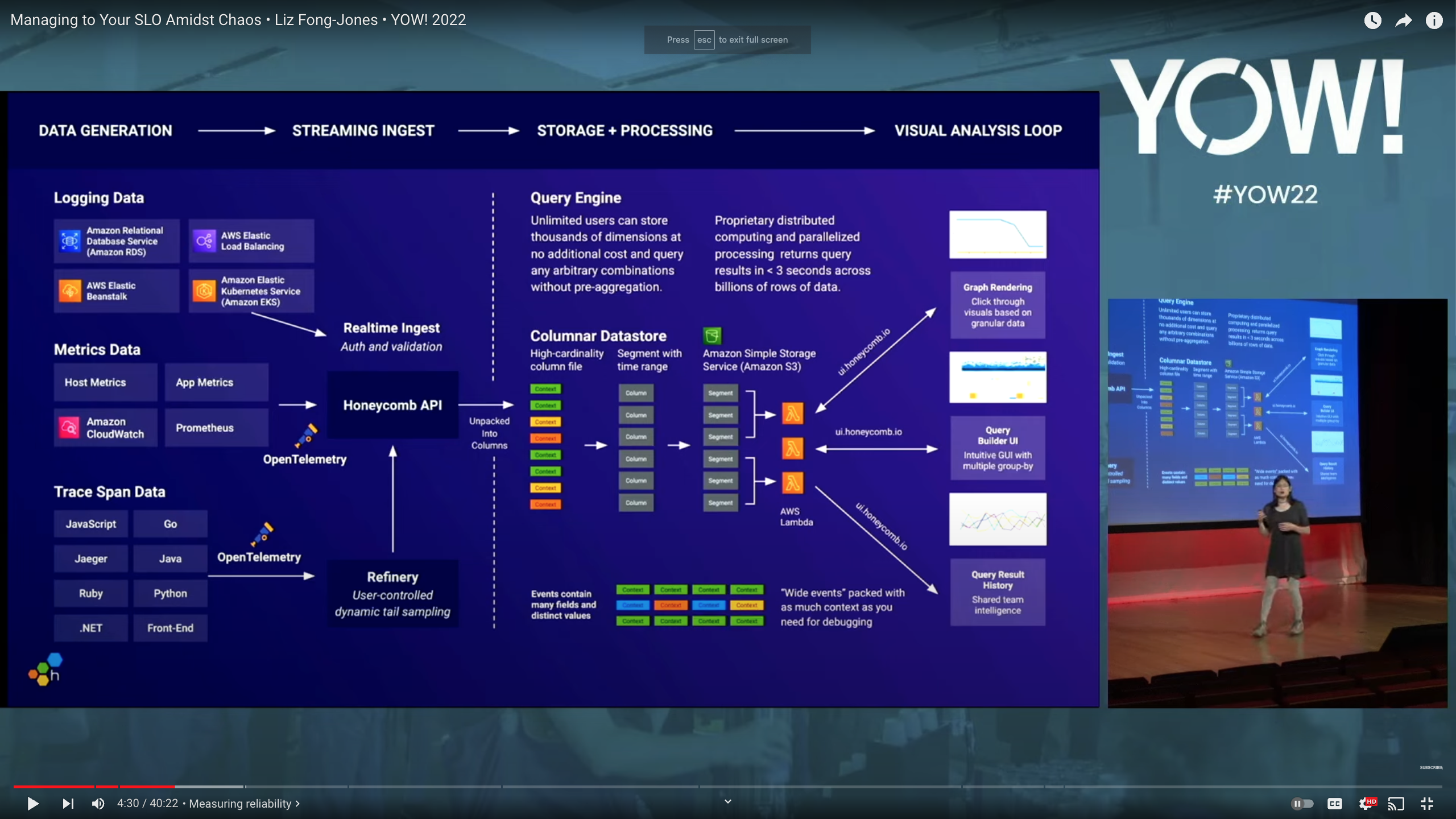
- Managing to Your SLO Amidst Chaos • Liz Fong-Jones • YOW! 2022: Techtalk from Liz about how to move quickly in a small team, ship, and be reliable
- be deploying always (multiple times a day)
- 2mil data points ingested per second
- ask first what is the expected amount of reliability from customers which helps a team set service level objectives (slos)
- Measure critical user journeys and determine which % need to complete successful for user expectations to be met
- alert based on slos primarily gives a good sense of how the system is performing (directly relates to customer pain)
- honeycomb slos
- homepage loads fast (99.99% of events process without error over 30 days)
- query runs fast (99.99% of events process without error over 30 days)
- ingest happens fast (99.99% of events are ingested in under 5ms over 30 days)
- means ~4.5mins of violation a month
- feature flags
- devs ship when work is done not x days in the future when they really know how the thing they just wrote is supposed to work
Data flow diagram