


Reinvent 2022 breakout session notes
Conference videos came out really early this year. I like to write down the highlights for me as I go so this is a post for that. I will not be watching all the things. That would be insane.
- Build production-ready prototypes rapidly using serverless patterns (ARC311-R)
- Excellent end to end talk of building a prototype quickly to prod with the correct amount of energy from the team along the way
- Serverless components are used to help minimize code but you end up with lots of config related to describing serverless things and how they connect. You’re always tightly bound to aws but this is a tradeoff.
- Do you actually get developer velocity gains + other things like observability baked in at least somewhat?
- CDK and SAM from AWS provide predefined higher order constructs that could help speed things along (eg apigateway + cognito -> lambda -> dynamo)
- Parameter store is used to eliminate direct dependencies between stacks, and other system resources
- The Amazon Builders’ Library: 25 yrs of Amazon operational excellence (DOP301): Great overview of the builders’ library. Walks through incident response, deployment of software changes and infrastructure changes, as well as how to go about making breaking backwards incompatible changes.

- Escalate early. We often want to fix a problem without having to bug somebody or wake somebody up but it’s better to get experts involved sooner so a production event can be resolved.
- Amazon rolls back frequently when they encounter errors.
- S.A.F.E: Stay calm, assess the situation, focus on mitigation, escalate early.
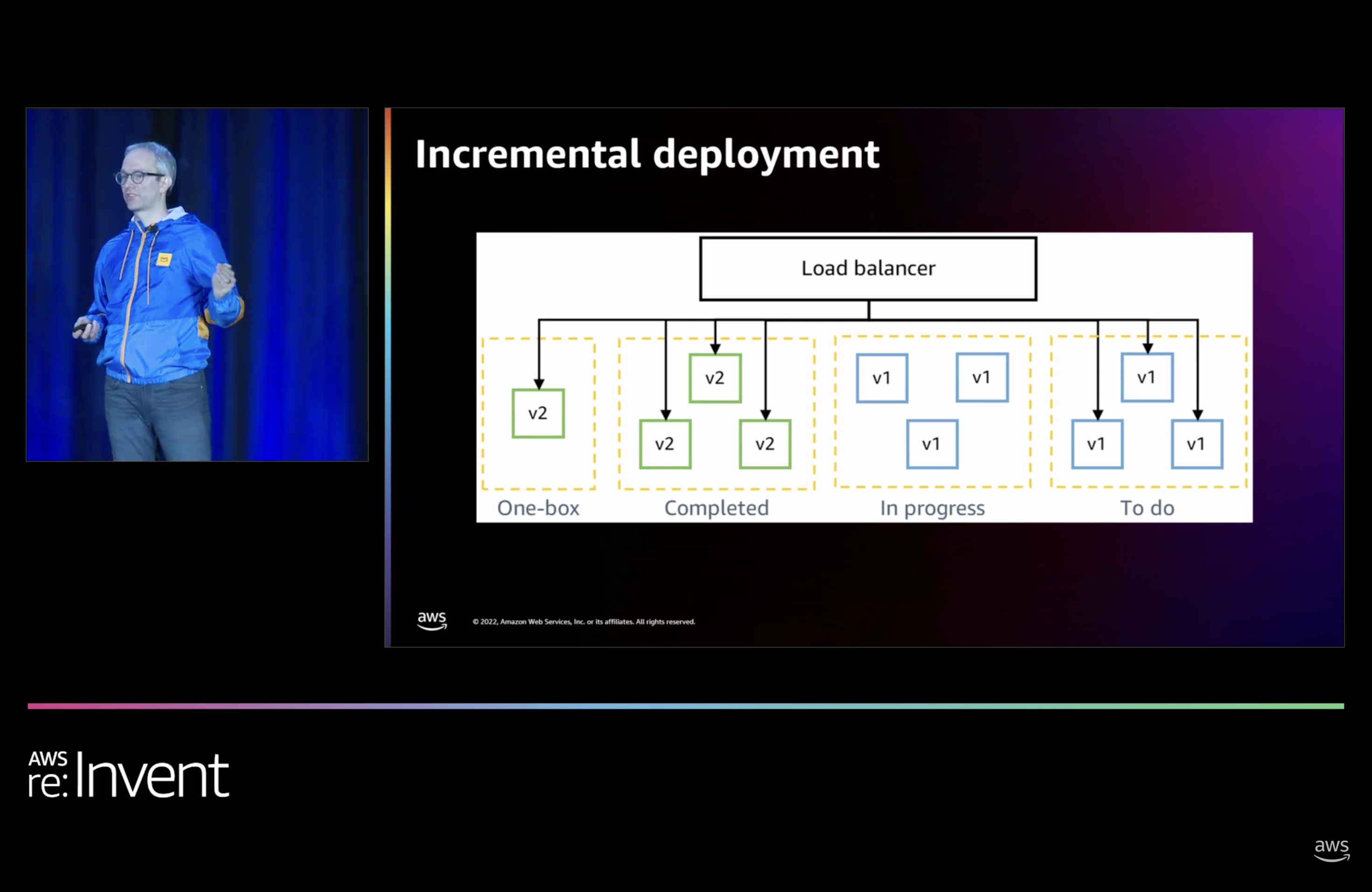
- Deployer at aws deploys to successively larger server groups as confidence in a change goes up. Confidence builds by a previous step looking healthy. 1 server (or <1% of traffic), n servers (some number bounded by an az), multi-az, multi-region, etc.
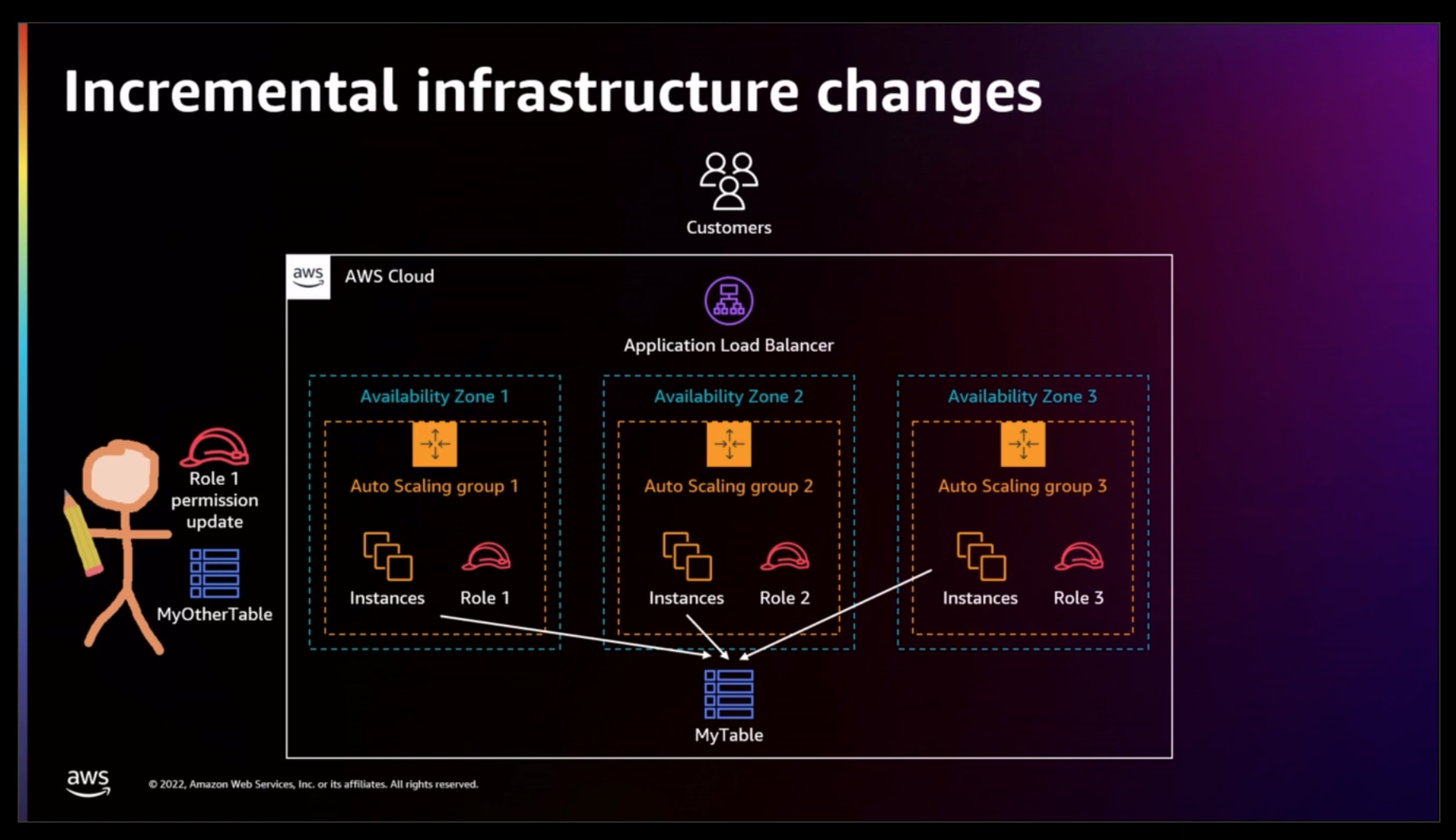
- Infra as code definition aligns with physical systems. eg 1 autoscaling group and iam server role per az for a service spanning 3 azs means you can plan to make a change that only impacts a subsets of server resources. (vs Configuring 1 asg + role that spans all azs which means every change hits the entire service at the same time.)
