


The cost of new tools
An amazing thread by Charity majors here. I already added the start of the thread to my quotes page but there’s so much more good stuff being said that I wanted to capture more!
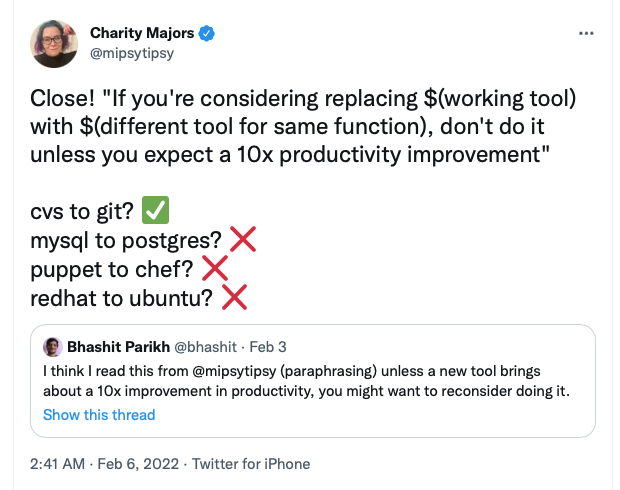
This statement started it:
- I think I read this from @mipsytipsy (paraphrasing) unless a new tool brings about a 10x improvement in productivity, you might want to reconsider doing it.
And here’s where she went:
- Close! “If you’re considering replacing $(working tool) with $(different tool for same function), don’t do it unless you expect a 10x productivity improvement”
- The costs of ripping and replacing, training humans, updating references and docs, the overhead of managing two systems in the meantime, etc – are so high that otherwise you are likely better off investing that time in making the existing solution work for you.
- Of course, every situation is unique. And the interesting conversations are usually around where that 10x break-even point will be. The big one of the past half-decade has been when to move from virtualization to containerization.
- You’d think it would have been driven by technical reasons – build times, security, quality and range of available tooling. But no; from where I sit, it seems to have been driven by circular human reasons. K8s is the cool thing to work on, the cool people want to work on k8s…
- This often comes up in the context of observability. Does a company need true observability, with high cardinality, high dimensionality and explorability, or can they stumble along fine with prometheus, metrics and logging and the like?
- It’s definitely true that the more “modern” your infra stack is (multiple services, storage systems, code running on third parties, etc) the more non negotiable observability becomes. There is a point past which you literally cannot do your job without it.
- Whereas if you run on a basic LAMP stack, with a low degree of infra dynamism, you can handle things quite well with metrics and logs. And you SHOULD try to keep things as simple as possible, for as long as possible.
- But making these decisions wisely is never about how many machines you have or what software they are running. Those are just heuristics that help us estimate complexity. In the end, it always comes down to where your people are spending time and energy and getting frustrated.
- If your team is running a massive fleet of microservices that are well understood using only metrics and logs – if they can ship changes swiftly, onboard new team members, and spend little time debugging, reproducing or recovering from errors – you don’t need observability.
- Conversely, if they are spending their time staring at code and trying to extrapolate behavior, adding and deleting bursts of print statements, or if your customers are suffering, then you need instrumentation and o11y. Even if you’re running the world’s simplest architecture,