- AWS re:Invent 2021 - DynamoDB deep dive: Advanced design patterns: Talk by Rick Houlihan about the evolution of databases from the general ledger (written by hand hundreds of years ago) to the relation and nosql systems we have today
- Note nosql is not non-relational. All data is relational
- oltp systems can be a good fit for nosql
- tradeoff in cpu time vs storage. When cpu was cheaper than disk we’d de-dupe data with 3rd normal form (Codd) by stuffing it in homogeneous buckets (1 table per entity eg order_items) and joining to recover a complete entity which would burn a ton of cpu
- cpu was cheaper than disk and getting cheaper quicker (moore’s law)
- These days storage is getting cheaper every year. Processors have stopped scaling in the same way (as of ~2014)
- SQL stores are good for olap type applications where you don’t understand the access patterns
- When designing a nosql system you want your data model to line up well with how your app will be using it (use cases, access patterns, etc)
- Reads start with indexes
- Create as many indexes as you need
- Indexes represent a novel partitional / grouping of your underlying data
- Indexes will duplicate data
- This is fine
- Operational characteristics are pretty cool
- Scale by partitioning data across storage nodes
- Sharding baked in by use of partition key (primary + secondary key for an index?)
- burst read / write credits for a table (any provisioned capacity not used in the previous 5m becomes available now for surge handling)
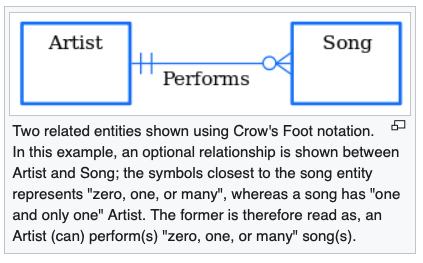
- ER Diagraming Crow’s Foot notation: I’ve bumped into er diagrams a few times recently. Here’s a note to remind myself how to read them