


SRECon Notes '21
Don’t Follow Leaders or “All Models Are Wrong (and So Am I)”
- Speaker: Nial Murphy
- Questions about the sre model as the high watermark of the way we work in operations (Or between operations and dev)
- It is a model
- It is not the only model or the last model we will ever have
- We should keep moving the field forward
- The desire for reliability as a driver for future engineering energy vs other forces (Is it always the most important thing we do? Not always. Fact: It doesn’t always win every prioritization battle.)
- “The value of reliability”
- There is definitely but it’s a more subtle thing
- Much evidence that reliability can be safely ignored in some cases for some amount of time
- SLOs
- Value in “social interaction between business and the need / desire for reliability work”. eg When to react or not …
- SLOs can’t distinguish between 1x 100min outage and 100x 1min outage
- Charity Majors: 9s don’t matter if the user isn’t happy
- 9s are a proxy for user happiness. There are other measures
- There’s a spectrum of availability and experience for users
- “What about this infrastructure maps to good human experience?”
- Value in sre
- Lots of people start and stop here: oncall
- A couple others
- preventative measures
- think about design constraints
Optimizing Cost and Performance with arm64
- Speaker: Liz Fong Jones
- Dramatic cost + performance improvements for their workloads
- Experiments into new cpu platform performed in small increments over time since it was identified that there could be excitement here just because they were early movers
- Prioritize health / wellbeing of people first whenever experimental work like this is being done
- ARM64 is pretty incredible in terms of cost / performance
- I think … 3x boost in amount of work most services were doing (good because their business grew quite a bit in 2020) and only 10% increase in cost because the machines were just that much better
- Kafka was a failure they rolled back. They experienced a few major failures that made them feel it was better to just roll that service back
- At the time they were doing the migration work kafka hadn’t really been run in that environment before at that scale and there were just issues and learnings to chew on
- Java + Go were relatively easy to target the different instruction set of the arm64
- Java code compiles to intermediate instruction set (Idealized machine?) and then to machine code at runtime
- Go compiler can be told to produce intel vs arm type instructions in a command line flag
Capacity Management for Fun & Profit
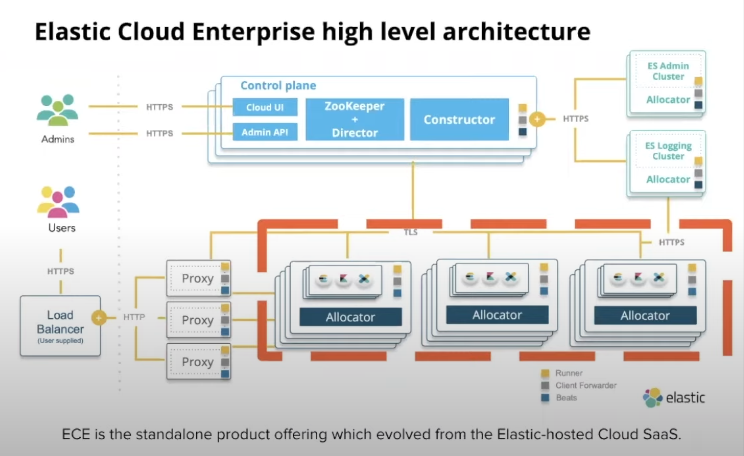
- Speaker: Aly Fulton @ Elastic
- Home grown tooling for managing fleets across aws, gcp, azure
- SREs own scaling things up / down
- I don’t think they’re using plain vanilla autoscaling on its own (elastic is a stateful thing - can’t just spin servers up and down)
- Pack nodes into big servers (58g ram)
- Elastic prices vms largely by memory I guess
- They have allocator nodes that are in charge of capacity. Not quite sure what responsibilities are here:
- “Contain nodes for ES clusters” which doesn’t imply 1:1 here. She talks about binpacking a few times which makes me think a single server is running multiple nodes (58g std size … I think the largest instance type they sell is 58g so that’d be a single tenant. Anything less than that is probably shared.)
- I guess allocators run an agent that starts an es container?
- I wonder if there is 1 elastic process per allocator
- or 1 process per tenant per allocator
- Is elastic multitenant with reasonable isolation (/boundary) controls?
Hard Problems We Handle in Incidents but Aren’t Recognized
- Speaker: John Allspaw
- Diagnose (try to figure out what’s going on), therapy (do things you think will help), recruit (people to the team)
- Cost of coordination (Laura Maguire)
- Tradeoff: When recruiting, do you keep investigating an incident or do you bring somebody up to speed so that they can help work the incident
- Every action or judgement has a cost (We don’t always acknowledge this) : coordinate / scatter gather
/ identify constituent tasks / pick someone to work on it
- Are you pulling somebody off a more important task?
- Sacrifice choices
- eg Kill a long running query, Force a network partition, Shut down the system why an investigation is in progress
- You will be judged by observers without the context you have in the moment (Hindsight bias)
- Expertise is invisible
- Hard to see
- Hard to describe
Followup video: The secret lives of SREs